
様々な学習理論について見ていきましょう。
バラス・フレデリック・スキナー(B.F.Skinner)は、人や動物の行動をレスポンデントとオペラントに分類しました。
まずは、レスポンデント行動は条件反射的な行動、オペラント行動は学習による行動というザックリとした理解を。
レスポンデントはレスポンス(response)=「反応する」、オペラントはオペレイト(operate)=「動作する」から作られた造語です。
レスポンデント条件づけ(古典的条件づけ)by パブロフ
「レスポンデント条件づけ」は、条件刺激を提示した後に無条件刺激を提示することで無条件反応を引き起こすものです。
代表的な例では、イワン・ペトローヴィチ・パブロフ(I.P.Pavlov)の「パブロフの犬」という実験が有名です。
実験:パブロフの犬
この実験は、犬にベルを鳴らして餌を与えるとベルを鳴らすだけでよだれを垂らすようになったというものです。
これは学習によって能動的によだれを出しているのではなく、条件反射的によだれが出ているのでレスポンデント行動です。
逆行条件づけ&順行条件づけ
パブロフの犬で、「ベルを鳴らす→餌を与える」(順行条件づけ)ではなく、「餌を与える→ベルを鳴らす」(逆行条件づけ)というように、条件刺激が無条件刺激に後行する場合、反応の獲得は難しくなります。
オペラント条件づけ by スキナー
「オペラント条件づけ」は、報酬や嫌悪刺激に適応して自発的にある行動を行うように学習することです。
オペラントとレスポンデントの違いは能動的か受動的かで区別しましょう。
実験:スキナー箱
バラス・フレデリック・スキナー(B.F.Skinner)は、ネズミを箱に入れて、中にあるレバーを押すと自動的に餌が出てくる仕組みを学習する実験を行います。
はじめはレバーの仕組みがわからないのですが、たまたまレバーに触れて餌が出てくることを繰り返すと、学習によってレバーを自発的に押すようになるというものです。
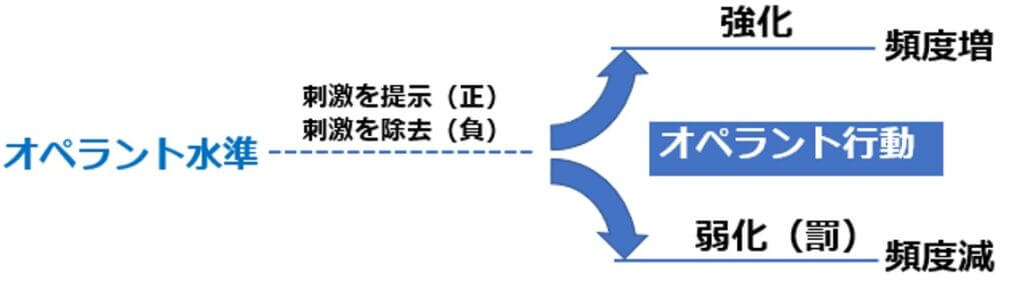
オペラント水準
オペラント条件づけによる行動変容以前の行動頻度を「オペラント水準」といいます。
正と負、強化と罰
オペラント条件づけでは、刺激を提示することを「正」、除去することを「負」といいます。
その刺激によって頻度が増加することを「強化」、減少することを「弱化(罰)」といいます。
・負の強化:刺激が除去されて頻度が増大
・正の罰:刺激が提示されて頻度が減少
・負の罰:刺激が除去されて頻度が減少
正の強化
正の強化は、例えば「宿題をやらなかった子が先生に褒められて宿題をやってくるようになる」というように、ご褒美によって頻度が増大する「報酬訓練」です。
この「正の強化」による行動療法に、トークンエコノミー法があります。
トークンエコノミー法は、良い行動をしたときに、トークンという代用貨幣をもらえることで、その行動を強化する方法です。
そのトークンは、本人の欲しいモノと交換ができ、その本人の欲しいモノのことを「バックアップ強化子」と言います。
また、不適切な行動が見られた場合は、トークンを没収しますが、この手続きを「レスポンスコスト」といいます。
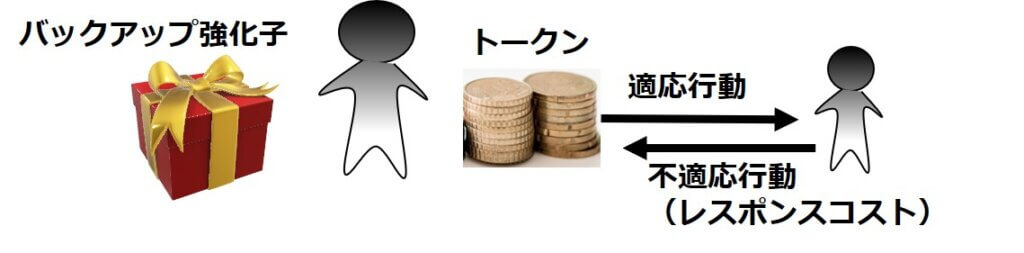
トークンエコノミー法は、トークンを与えて適応行動の頻度を上げるので「正の強化」、レスポンスコストは、トークンを没収して不適応行動の頻度を下げるので「負の罰」ということで、全く異なる手法です。
負の強化
負の強化は、例えば「薬を飲んだら頭痛が治ったので薬をすぐに飲むようになった」というように、「逃避学習」や「回避学習」が典型例です。
正の罰
正の罰は、例えば「いたずらをしたら叱られたのでいたずらをやめた」というような「罰訓練」です。
負の罰
負の罰は、例えば、問題行動がある子供を一定時間小部屋に入れて沈静化させて問題行動を減少させる「タイムアウト法」があり、「オミッション訓練」と呼ばれます。
先ほど出て来た「レスポンスコスト」も負の罰の例ですね。
まとめ
| 強化 | 弱化(罰) | |
|---|---|---|
| 正 | 報酬訓練 | 罰訓練 |
| 負 | 逃避学習、回避学習 | オミッション訓練 |
間欠強化(間歇強化)&連続強化
オペラント条件づけには「間欠強化」と「連続強化」があります。
「間欠強化」はご褒美があったりなかったりすることによる強化、「連続強化」はご褒美が必ずあることによる強化で、それぞれにメリットとデメリットがあります。
例えば、ツンデレの人はモテやすいというのは間欠強化の例ですね。
反応を形成するには連続強化のほうが効果的ですが、反応を維持するためには間欠強化のほうが効果的です。
そして、連続強化よりも間欠強化の方が、学習の消去が起こりにくい(消去抵抗が大きい)です。
三項強化随伴性
オペラント行動には、オペラント反応が引き起こされる「先行事象」があり、オペラント行動後の「後続事象」があります。
時間の流れで表すと、先行事象→オペラント行動→後続事象となり、これら3つは強化によって随伴するので三項強化随伴性と呼ばれます。
オペラント反応が自発される手がかりを与えるようになった刺激(先行事象)は「弁別刺激」と呼ばれます。
弁別刺激(先行事象)→オペラント反応(オペラント行動)→強化刺激(後続事象)
それぞれの頭文字をとってABC分析とも呼びます。
①先行事象(Antecedent)
②標的行動(Behavior)
③後続事象(Consequence)
応用行動分析では、標的行動と前後の先行事象・後続事象との機能的な関係を明らかにすることを「機能分析」と呼びます。
試行錯誤学習 by ソーンダイク
実験:猫の問題箱の実験
ソーンダイク(E.L.Thorndike)は、スキナーと同じような実験をネコで行っています。
ソーンダイクの猫の実験の方が先で、その後スキナーがネズミによって体系的に実験を行いました。
空腹の猫を箱に入れ、外側に餌を置いておきます。箱の中の紐を引くと外に出られて餌を食べらるのですが、初めはその仕組みがわからず、たまたま紐が引かれて外に出られる経験を繰り返すことで学習し、徐々に短時間で外に出られるようになるというものです。
このように試行錯誤によって学習するので「試行錯誤学習」と呼ばれます。

ソーンダイクは大工さんのように試行錯誤したと覚えよう。
潜在学習 by トールマン
実験:ネズミの迷路学習
エドワード・チェイス・トールマン(E.C.Tolman)は、ネズミの迷路学習実験で「潜在学習」を見出しています。
このネズミの実験は、ゴール地点に餌がなくても事前に迷路を走る経験から「認知地図」を作り出し、いざ餌が与えられたらその地図を内的に読みながら素早くゴール地点に向かえるようになります。
この「潜在学習」は、報酬がない時期に潜在的に進行していた学習が、報酬によって顕在化するという学習の形態です。
まとめ
| 年 | 人物 | キーワード | 実験 |
|---|---|---|---|
| 1902年 | I.P.パブロフ | 古典的条件づけ | パブロフの犬(イヌ) |
| 1911年 | E.ソーンダイク | 試行錯誤学習 | 試行錯誤実験(ネコ) |
| 1930年 | E.C.トールマン | 認知地図、潜在学習 | 迷路学習実験(ネズミ) |
| 1938年 | B.F.スキナー | オペラント条件づけ | スキナー箱(ネズミ) |
実験に出てくる動物の順番が、犬、猫、ネズミと変わっているね。
犬猫は可哀そうだからね。
過去問
第1回 問5
オペラント行動の研究の基礎を築いたのは誰か。正しいものを1つ選べ。
① A. Adler
② B. F. Skinner
③ E. C. Tolman
④ I. P. Pavlov
⑤ J. B. Watson
① A. Adler
心理学の三大巨頭のひとりアルフレッド・アドラーは、アドラー心理学を作った人です。
② B. F. Skinner
これが正解、バラス・フレデリック・スキナーです。
③ E. C. Tolman
トールマンといえば「潜在学習」です。
④ I. P. Pavlov
パブロフと言えば「パブロフの犬」です。
⑤ J. B. Watson
ワトソンと言えば「行動主義心理学」です。
第1回 問7
条件づけについて、正しいものを1つ選べ。
① 貨幣やポイントを強化子とした条件づけを二次条件づけと呼ぶ。
② 古典的条件づけは、条件刺激と無条件反応の連合によって成立する。
③ オペラント条件づけによる行動変容以前の行動頻度をオペラント水準と呼ぶ。
④ 連続強化による条件づけは、間歇強化による条件づけよりも消去抵抗が強い。
⑤ 古典的条件づけにおいては、逆行条件づけは順行条件づけよりも条件反応の獲得が良好である。
① 貨幣やポイントを強化子とした条件づけを二次条件づけと呼ぶ。
間違いです。これはトークンエコノミー法です。
② 古典的条件づけは、条件刺激と無条件反応の連合によって成立する。
間違いです。古典的条件づけは、条件刺激と無条件刺激の連合により、反応が変化することをいいます。
③ オペラント条件づけによる行動変容以前の行動頻度をオペラント水準と呼ぶ。
これが正解です。
④ 連続強化による条件づけは、間歇強化による条件づけよりも消去抵抗が強い。
間違いです。連続強化による条件づけは、間歇強化による条件づけよりも消去抵抗が弱いです。
⑤ 古典的条件づけにおいては、逆行条件づけは順行条件づけよりも条件反応の獲得が良好である。
間違いです。古典的条件づけにおいては、逆行条件づけは順行条件づけよりも条件反応の獲得が良好ではありません。
第1回 問39(追試)
オペラント条件づけで、逃避学習や回避学習を最も成立させやすいものとして、正しいものを1つ選べ。
① 正の罰
② 負の罰
③ 正の強化
④ 負の強化
選択肢④が正解です。
第5回 問86
行動の学習について、正しいものを1つ選べ。
① 古典的条件づけでは、般化は生じない。
② 味覚嫌悪学習は、脱馴化の典型例である。
③ 部分強化は、連続強化に比べて反応の習得が早い。
④ 危険運転をした者の運転免許を停止することは、正の罰である。
⑤ 未装着警報音を止めるためにシートベルトをすることは、負の強化である。
選択肢⑤が正解です。
第1回(追試)問89
トークンエコノミー法について、正しいものを1つ選べ。
① タイムアウトを活用する。
② レスポンスコストに基づく。
③ 賞賛によって行動を強化する。
④ バックアップ強化子(好子)を用いる。
⑤ 問題行動の減少を主要な目標とする。
① タイムアウトを活用する。
間違いです。タイムアウトとは、子ども等が不適切な行動をとったときに、一時的に部屋に閉じ込める事です。
② レスポンスコストに基づく。
間違いです。レスポンスコストは、不適切な行動をとったときに、トークンを没収することで、その不適切行動の頻度が低下するという原理に基づいています。
③ 賞賛によって行動を強化する。
間違いです。トークンエコノミー法は、賞賛ではなくトークンというご褒美によって行動を強化します。
④ バックアップ強化子(好子)を用いる。
これが正解です。
⑤ 問題行動の減少を主要な目標とする。
間違いです。トークンエコノミー法は望ましい行動を強化することを目標とします。
第2回 問9
ある刺激に条件づけられた反応が他の刺激に対しても生じるようになることを何というか、正しいものを1つ選べ。
① 馴化
② 消去
③ 般化
④ シェイピング
⑤ オペラント水準
① 馴化
間違いです。馴化とは、同一の刺激を繰り返し経験するとその刺激に対する反応が弱まってくる現象のことです。文字通り「馴れる」ことです。
② 消去
間違いです。消去とは、オペラント条件づけによって形成された行動について、強化を与えないことで形成された行動がみられなくなることです。
③ 般化
これが正解です。
④ シェイピング
間違いです。シェイピングとは、スモールステップで目標に近づけていく方法のことです。
⑤ オペラント水準
間違いです。オペラント水準とは、オペラント条件づけによる行動変容以前の行動頻度のことです。
第3回 問10
E.C.Tolman は、ラットの迷路学習訓練において、訓練期間の途中から餌報酬を導入する実験を行っている。この実験により明らかになったこととして、最も適切なものを1つ選べ。
① 回避学習
② 観察学習
③ 初期学習
④ 潜在学習
⑤ 逃避学習
選択肢④が正解です。
第4回 問137
30歳の男性A、会社員。
喫煙をやめたいがなかなかやめられないため、会社の健康管理室を訪れ、公認心理師Bに相談した。
Bは、Aが自らの行動を観察した結果を踏まえ、Aの喫煙行動を標的行動とし、標的行動の先行事象と結果事象について、検討した。
先行事象が、 ”喫煙所の横を通ったら、同僚がタバコを吸っている”であるとき、結果事象として、最も適切なものを1つ選べ。
① 喫煙所に入る
② タバコを吸う
③ 同僚と話をする
④ 自動販売機で飲み物を買う
⑤ コンビニエンスストアでタバコを買う
選択肢③が正解です。三項強化随伴性を考えると、
同僚がタバコを吸っている(先行事象)→タバコを吸う(標的行動)→同僚を話をする(結果事象)となります。
次の記事
次は学習心理学です。学習性無力感を含めた様々な学習を見ていきましょう。



コメント
こんにちは。福岡のazと申します。
早速、公認心理師受験用の解説が増えていて驚きました!オペラント条件づけ関連は、表面的な理解だったので助かります。ありがとうございます。しっかり読み込みます!
あと、私も会員になれるのでしょうか?社福は取得見込みです。もし会員条件を満たせていたら、ぜひ会員になりたいです。宜しくお願い致します。
これから記事をどんどん追加していきます。
お役に立てるようにがんばります!
会員も募集中です。
社会福祉士に合格された方なら会員になっていただいてもほとんど意味はないのですが、それでもよければ大歓迎です。